|
Haodong Li I'm a second-year M.Phil. student at HKUST (Guangzhou), working with Prof. Ying-Cong Chen. I'm currently doing an internship at Tencent Hunyuan (3D Generation Group). I got my B.Eng. degree from Zhejiang University. My research interests include 3D/4D Vision and Generative Models. Feel free to contact if you have anything to discuss! |

|
Research✱: Both authors contributed equally. |

|
LOTUS: Diffusion-based Visual Foundation Model for High-quality Dense Prediction
Jing He✱ , Haodong Li✱ , Wei Yin, Yixun Liang, Leheng Li, Kaiqiang Zhou, Hongbo Zhang, Bingbing Liu, Ying-Cong Chen
ICLR 2025
Lotus is a diffusion-based visual foundation model with a simple yet effective adaptation protocol, aiming to fully leverage the pre-trained diffusion's powerful visual priors for dense prediction. With minimal training data, Lotus achieves SoTA performance in two key geometry perception tasks, i.e., zero-shot monocular depth and normal estimation. |



|
DisEnvisioner: Disentangled and Enriched Visual Prompt for Image Customization
Jing He✱ , Haodong Li✱ , Yongzhe Hu, Guibao Shen, Yingjie Cai, Weichao Qiu, Ying-Cong Chen
ICLR 2025
Characterized by its emphasis on the interpretation of subject-essential attributes, the proposed DisEnvisioner effectively identifies and enhances the subject-essential feature while filtering out other irrelevant information, enabling exceptional image customization without cumbersome tuning or relying on multiple reference images. |


|
DIScene: Object Decoupling and Interaction Modeling for Complex Scene Generation
Xiao-Lei Li✱ , Haodong Li✱ , Hao-Xiang Chen, Tai-Jiang Mu, Shi-Min Hu
SIGGRAPH Asia 2024
DIScene is capable of generating complex 3D scene with decoupled objects and clear interactions. Leveraging a learnable Scene Graph and Hybrid Mesh-Gaussian representation, we get 3D scenes with superior quality. DIScene can also flexibly edit the 3D scene by changing interactive objects or their attributes, benefiting diverse applications. |
|
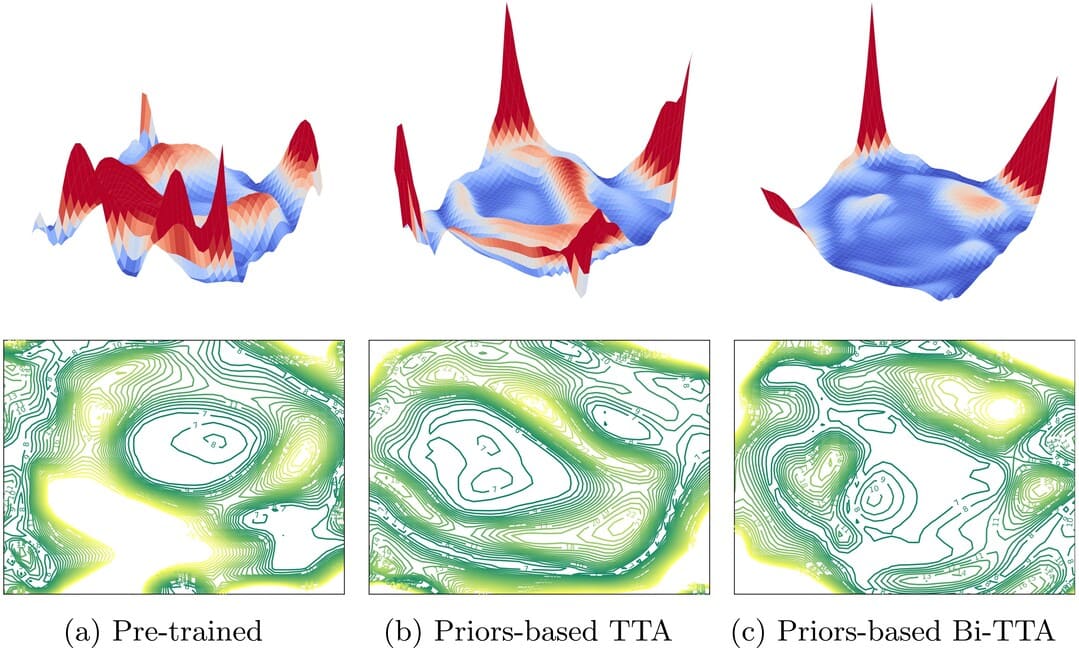
Bi-TTA: Bidirectional Test-Time Adapter for Remote Physiological Measurement
Haodong Li, Hao Lu, Ying-Cong Chen
ECCV 2024
We introduce Bi-TTA, a method that leverages spatial and temporal consistency for appropriate self-supervision, coupled with novel prospective and retrospective adaptation strategies, enabling superior adaptation ability of pre-trained rPPG models to the target domain using only unannotated, instance-level target data. |

|
LucidDreamer: Towards High-Fidelity Text-to-3D Generation via Interval Score Matching
Yixun Liang✱ , Xin Yang✱ , Jiantao Lin, Haodong Li, Xiaogang Xu, Ying-Cong Chen
CVPR 2024 Highlight
We present LucidDreamer, a text-to-3D generation framework, to distill high-fidelity textures and shapes from pretrained 2D diffusion models with a novel Interval Score Matching objective and an advanced 3D distillation pipeline. Together, we achieve superior 3D generation results with photorealistic quality in a short training time. |

Education |
|
|
Hong Kong University of Science and Technology
(2023/09 - Now)
Master of Philosophy Information Hub, Guangzhou Campus |
|
Zhejiang University
(2019/09 - 2023/06)
Bachelor of Engineering College of Control Science and Engineering |
Experience |

|
Tencent Hunyuan
(2025/05 - Now)
Research Intern 3D Generation Group |

|
University of Pennsylvania
(2024/07 - 2024/11)
Research Intern School of Engineering and Applied Science |
Thanks for visiting! |